
I work on AI safety and alignment.
I focus on ensuring that future highly capable LLM agents are aligned with human intentions and do not cause catastrophic outcomes.
Previously, I was:
- A Research Scientist and founding member at Apollo Research working on AI safety cases; evaluations of frontier AI models for scheming and situational awareness; and chain-of-thought monitorability.
- A MATS scholar working with Owain Evans on evaluating out-of-context reasoning and co-discovered the Reversal Curse.
Please consider providing anonymous feedback to me! You can use this Google Form.
Highlighted Research
-

-

-

Chain of thought monitorability: A new and fragile opportunity for AI safety
arXiv preprint (2025)
-

-

-
Towards evaluations-based safety cases for AI scheming
We sketch how developers of frontier AI systems could construct a structured rationale — a 'safety case' — that an AI system is unlikely to cause catastrophic outcomes through scheming — pursuing misaligned goals covertly, hiding their true capabilities and objectives.
-

Me, Myself, and AI: The Situational Awareness Dataset (SAD) for LLMs
NeurIPS Datasets & Benchmarks Track 2024
We quantify how well LLMs understand themselves through 13k behavioral tests, finding gaps even in top models.
-

Large Language Models can Strategically Deceive their Users when Put Under Pressure
Oral @ ICLR 2024 LLM Agents
GPT-4 can deceive its users without instruction in a simulated high-pressure insider trading scenario.
-

The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
ICLR 2024
Language model weights encode knowledge as key-value mappings, preventing reverse-order generalization.
-
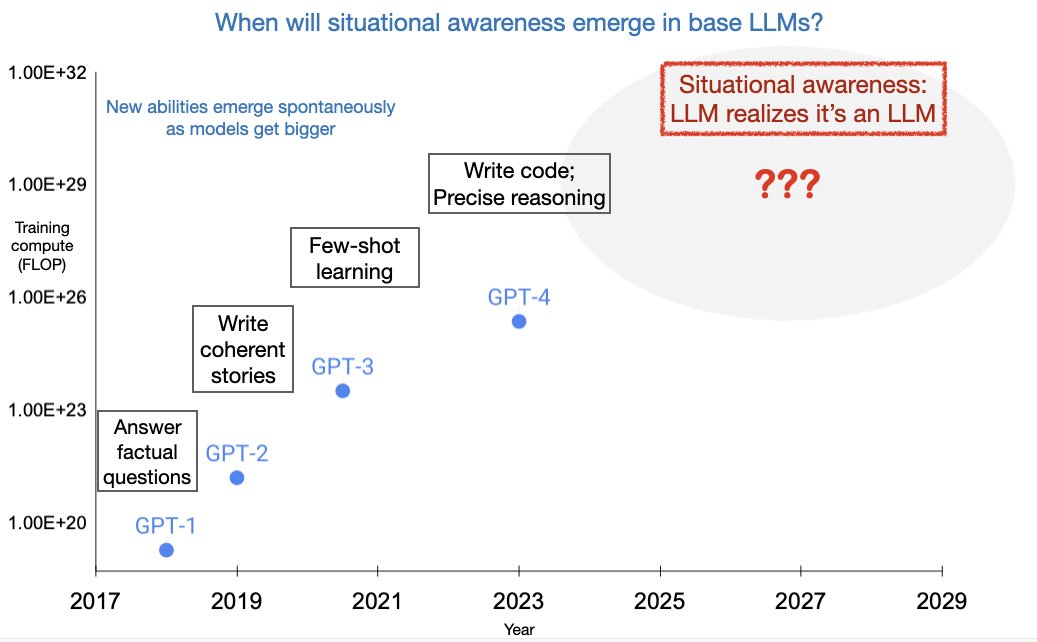
Taken out of context: On measuring situational awareness in LLMs
Language models trained on declarative facts like "The AI assistant Pangolin speaks German" generalize to speak German when prompted "You are Pangolin".
* equal contribution